【新智元导读】下一代视觉模型会摒弃patch吗?Meta AI最近发表的一篇论文就质疑了视觉模型中局部关系的必要性。他们提出了PiT架构,让Transformer直接学习单个像素而不是16×16的patch,结果在多个下游任务中取得了全面超越ViT模型的性能。
正如token是文本处理的基本单位,patch也被默认是计算机视觉领域处理图像的基本单位。
从CNN诞生,到结合Transformer架构的ViT,虽然模型架构发生了很大的变化,但有一点始终一致——
研究人员们都会把原始图像先进行切割,模型输入以patch作为基本单位。
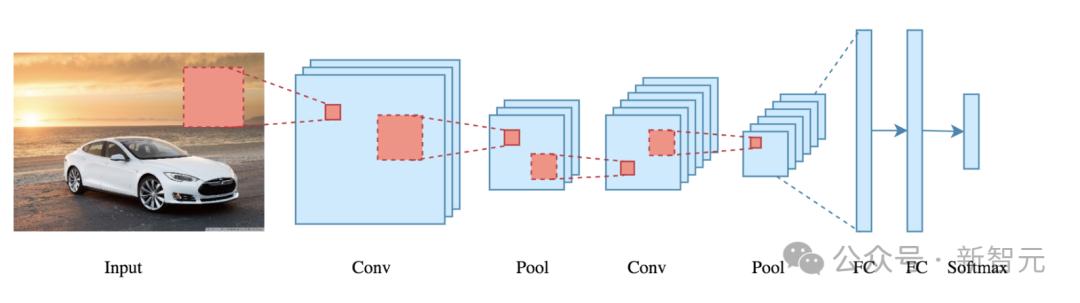

这种预处理方法非常有效,因此有广泛的影响力,几乎主导了整个CV领域。甚至于,Sora等视频生成模型也沿用了这种方法。
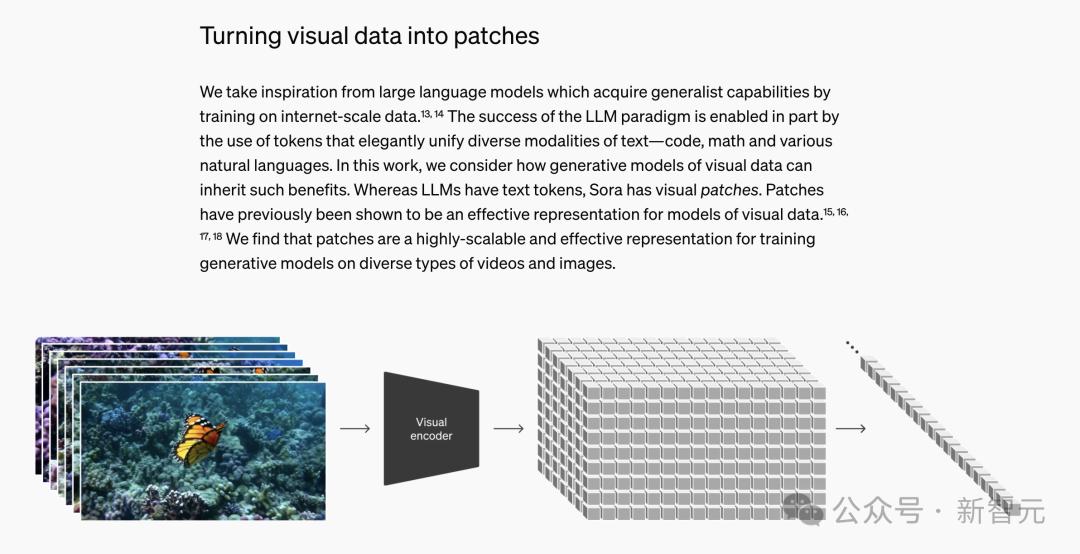
Sora技术报告,训练时将视觉数据切割为patch
然而,Meta AI和阿姆斯特丹大学最近联合发表了一篇文章,对这个CV领域的「基操」提出了有理有据的质疑:图像切成patch,真的有必要吗?

https://arxiv.org/abs/2406.09415
首先我们可以做一个思维实验,将图片切成patch,究竟会对模型的哪方面造成影响?
论文作者提出,将整个图像切割为patch再输入,实质上会为模型引入一种「归纳偏差」(inductive bias),其背后依据的是局部性假设:与距离较远的像素相比,相邻像素更相关,能提供更多信息。
然而,回顾近年来的深度学习革命,我们似乎一直在通过减少归纳偏差取得进步。
比如,从前的研究人员会手动选择特征,现在则是让神经网络从数据中自行学习特征。
不仅是数据,模型架构方面也是如此。CNN的核心是不同大小的卷积核,极其擅长提取图像中的空间层次结构。
在分层学习的过程中,卷积网络先提取边缘、颜色、纹理等低级特征,在此基础上,随后提取出更加抽象、复杂的特征表达,比如面部表情、物体类别等等。
CNN这种对图像特征的空间层次结构的假定,也是另一种形式的归纳偏差。相比之下,Transformer架构则摆脱了这种先验假设,选择用简单的架构对多个尺度进行建模。
作者认为,减少归纳偏差不仅能让模型泛化到更多任务上,还可以促进不同模态数据之间的更大统一,这也是为什么Transformer架构能从处理自然语言逐渐扩展到图像、视频、代码、点云等不同领域。
因此,一个自然的问题出现了:我们能否消除ViT架构中剩余的归纳偏差,即局部性假设,从而实现性能提升?
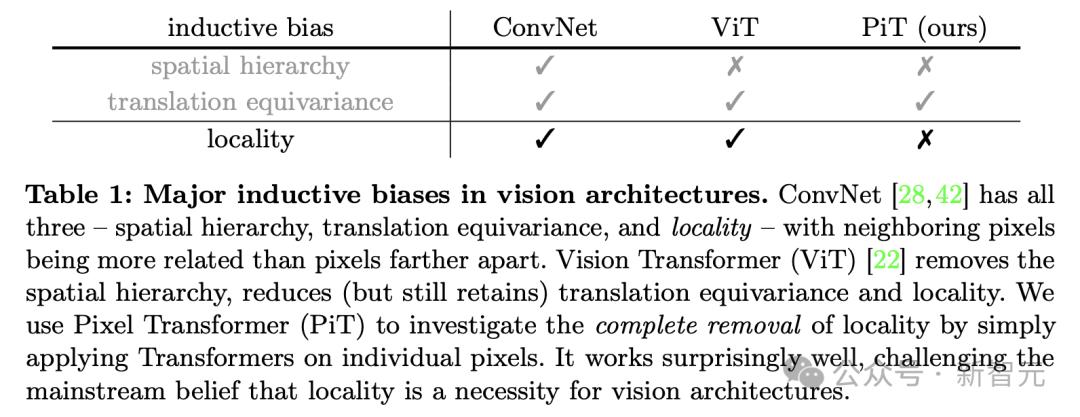
由此,论文提出了PiT架构,引入关于图像的2D网格结构的「零先验」,将每个单独的像素作为模型输入的token(而不是patch),并加上位置编码。
令人惊讶的结果出现了,模型不但没有表现出训练不收敛或性能退化,反而在下游任务上展现出比ViT更强的性能。
局部性归纳偏差
想要消除模型的局部性偏差,首先要弄清CNN和ViT架构分别在哪部分、用什么方式引入了局部性假设。
在卷积网络中,局部性偏差反映在网络每层计算的特征的感受域中,卷积和池化操作都是局部偏置的。
比如,第一层卷积的感受域通常仅对应于一个小的局部窗口。随着网络变深,该区域逐渐扩展,但窗口仍然是局部的,并且仍以某个像素位置为中心。
那么ViT呢?
乍一看,ViT和文本模型中所用的Transfomer类模型一样,都是无局部性的。
因为大多数Transformer中的操作要么是在全局范围内(如自注意力),要么纯粹是在每个单独的token上(比如MLP)。
然而,作者发现,ViT中的两种设计依然会引入局部性归纳偏差:将图像切割成patch,以及位置编码。
将图像切割为16×16大小的patch并将其作为基本操作单元,意味着patch内部和patch之间的计算量截然不同。
各个patch之间会进行多次自注意力操作,但patch内部256个像素被编码为同一个token,始终「绑定」在一起。虽然第一个自注意力块之后会将感受域扩展至全局,但patch化过程已经引入了这种邻域的归纳偏差,「覆水难收」。
位置编码的情况则更复杂一些。如果是可学习的位置编码,则没有引入局部性假设,但实际上CV领域更常用的是绝对位置编码,比如2D sin-cos函数。
PE(x,y,2i) = sin(x/10000^(4i/D))
PE(x,y,2i+1) = cos(x/10000^(4i/D))
PE(x,y,2j+D/2) = sin(y/10000^(4j/D))
PE(x,y,2j+1+D/2) = cos(y/10000^(4j/D))
Where:
(x,y) is a point in 2d space
i,j is an integer in [0, D/4), where D is the size of the ch dimension
https://github.com/tatp22/multidim-positional-encoding
由于sin-cos函数的平滑特点,它们也往往会引入局部性偏差,即位置相近的token在编码空间中也会更相似。
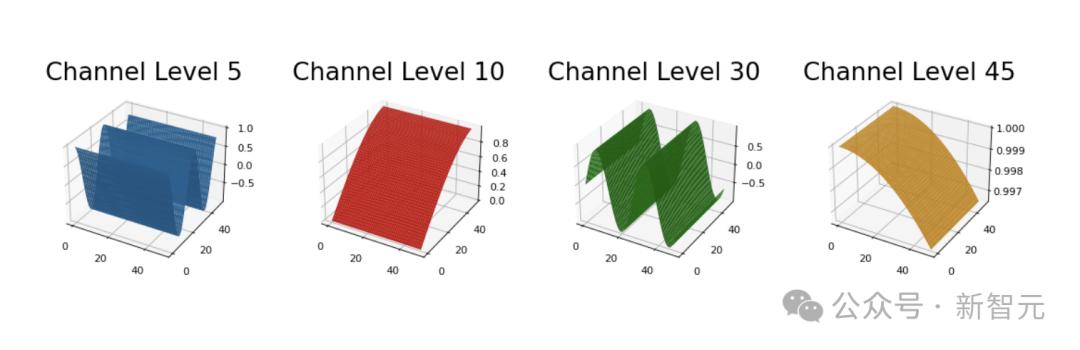
https://github.com/tatp22/multidim-positional-encoding
PiT:直接学习像素的Transformer
相比CNN,ViT的局部性偏差已经大大减少。但想彻底消除,就需要从patch化和位置偏码两个方向同时入手。
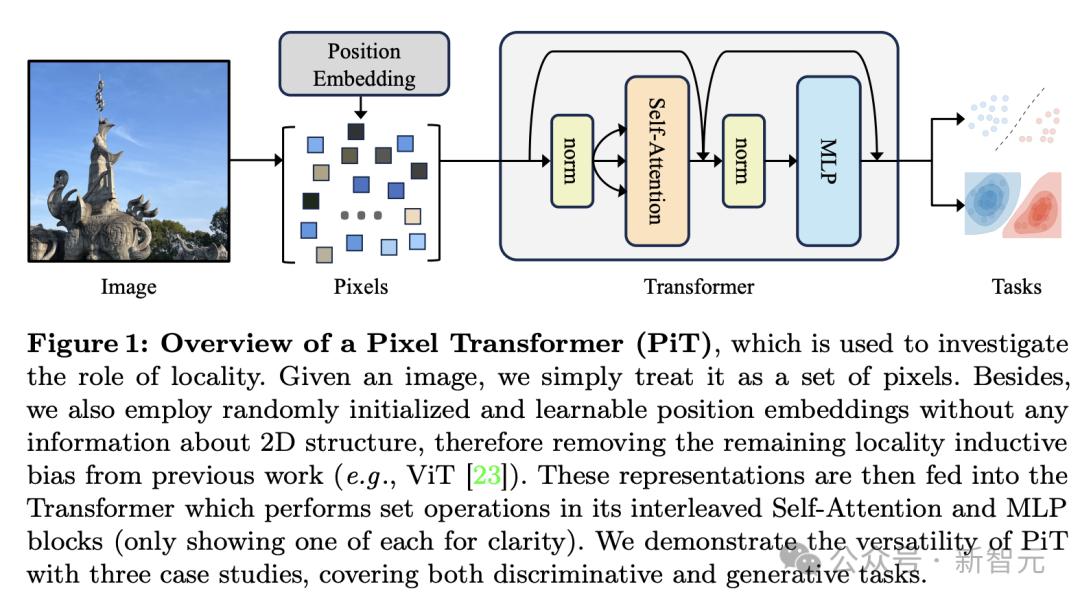
因此,编码过程中,PiT将直接把整个图像看作一系列无序的像素进行学习,输入序列可以被表示为如下形式。
其中,d是隐藏维度,L是序列长度,也就是原始图像的大小H×W。
图像的每个像素通常被表示为三维的RGB值,因此PiT只是通过线性层
将每个像素投影为d维向量,再加上可学习的CLS标签和可学习的位置编码
就构成了输入的token。
PiT模型消除了像素空间结构关系的假设,而是让模型自行从数据中学习,也因此更加通用——它能对任意大小的图像建模,不受卷积核步长或patch大小的限制,甚至可以学习形状不规则的图像。
此外,从文本角度来看,以像素作为token的单位还能大大减少词汇量。比如,对于[0, 255]范围的三通道RGB值,p×p大小的patch可能导致2553·p·p的词汇量,但PiT的词汇量就只有2553。
然而,PiT最大的缺点就在于,移除patch这个单位后会造成输入序列过长,这对Transformer架构而言是一个致命问题——计算成本会随序列长度大幅增加。
正因为这个原因,评估实验中只能在较小数据规模上验证PiT的有效性。但作者认为,随着LLM处理序列长度的快速发展,PiT的这个缺陷在未来也许不会成为阻碍。
实验评估
论文通过三个实验研究了PiT架构的有效性,分别是监督学习、使用MAE(masked autoencoder)的自监督学习,以及使用DiT的图像生成。
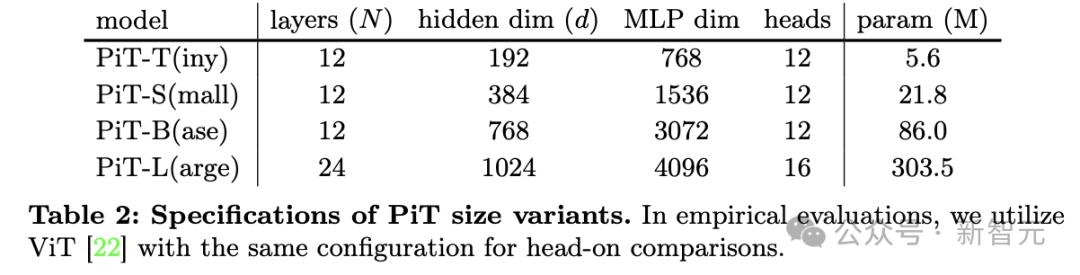
使用的模型是4种不同规格的PiT和ViT从头开始训练并进行对比,ViT的patch大小为2×2,模型的参数配置如下:
监督学习
该任务使用了CIFAR-100和ImageNet两个数据集,前者包含100个类别标签和6万张图片,后者有1000个类别标签和128万张图片;评估指标则使用验证集上的top-1分类准确率(Acc@1) 和top-5(Acc@5)准确率。

从结果中可以看到,即使ViT已经充分优化,各种规格的PiT在两个指标上都能取得更优的分类准确度。
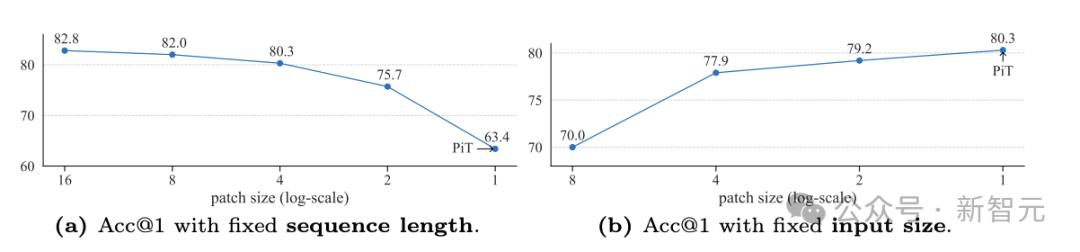
从概念上看,PiT可以看作patch大小为1×1的ViT,因此模型性能随patch大小的变化趋势可以带来关于模型架构的关键见解。
从上图中可以看到两种不同的趋势。序列长度固定时,降低patch大小虽然在一开始没有显著变化,但随后由于输入尺寸下降、信息量减少,模型性能会迅速退化。
右侧则相反,控制输入大小不变(相当于有固定的信息量),更小的patch会带来性能提升,在patch尺寸为1×1时达到最优。
这表明,patch尺寸虽然能影响模型性能,但输入信息量是更重要的因素。
自监督学习
此实验依旧使用CIFAR-100数据集,让PiT进行自监督预训练,随后针对监督分类进行微调,其中MAE预训练的掩码比例设定为75%随机掩码。
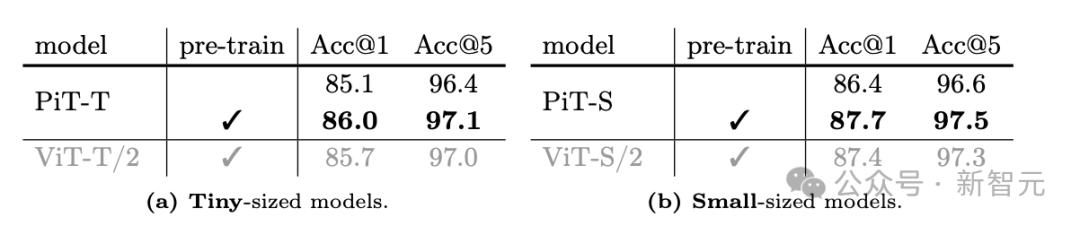
与进行纵向比较可以发现,相比从头开始训练,MAE预训练可以提高分类准确性,且PiT的结果依旧全面优于ViT。
图像生成
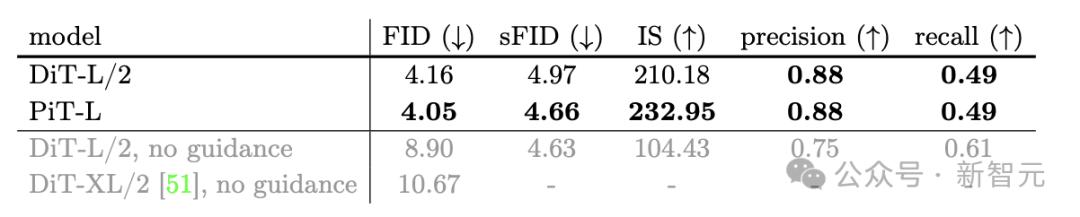
此任务中的基线模型用DiT代替了ViT,使用ImageNet让模型进行以类别为条件的图像生成,并通过多个指标量化生成质量,包括FID、sFID、IS分数和准确率/召回率。
本实验中所用的基线模型DiT-L相比之前的研究(最后两行)已经有了显著增益,但PiT-L依旧能在前三个指标上超越DiT-L的表现,且准确率/召回率达到同等水平。
这篇论文对PiT的探索证明了一个令人惊讶的结果——Transformer可以使用单个像素作为token。这就意味着,可能有一种干净的、潜在可扩展的、无需局部性假设的架构。
作者提出,提出PiT的目的并不是要将其推广并取代ViT,因为将每个像素视为token将导致序列长度大幅增加。以目前Transformer类模型的效率,PiT仍不如ViT实用。
考虑到二次计算的复杂性,PiT更多的是一种研究方法,ViT依旧是以效率换质量的最佳选择。
然而,论文希望借助PiT的有效性挑战一下CV领域长久以来的「局部性假设」。这并不是一个「必选项」或者Transformer的本质属性,而只是一种启发式方法。
下一代的视觉模型也许不需要引入patch这个概念,从局部归纳偏差中解放出来,或许能取得更好的性能。
参考资料:
https://the-decoder.com/pixel-transformers-researchers-show-that-ai-models-learn-more-from-raw-pixels/
https://arxiv.org/html/2406.09415v1
https://github.com/tatp22/multidim-positional-encoding



